2.1 Hardware Requirements for Specific AI Training Task Use Cases
What the exam tests
Matching AI workload types to the correct NVIDIA GPU/system, understanding why different workloads have different hardware needs (memory, bandwidth, FLOPS, form factor).
GPU selection by workload
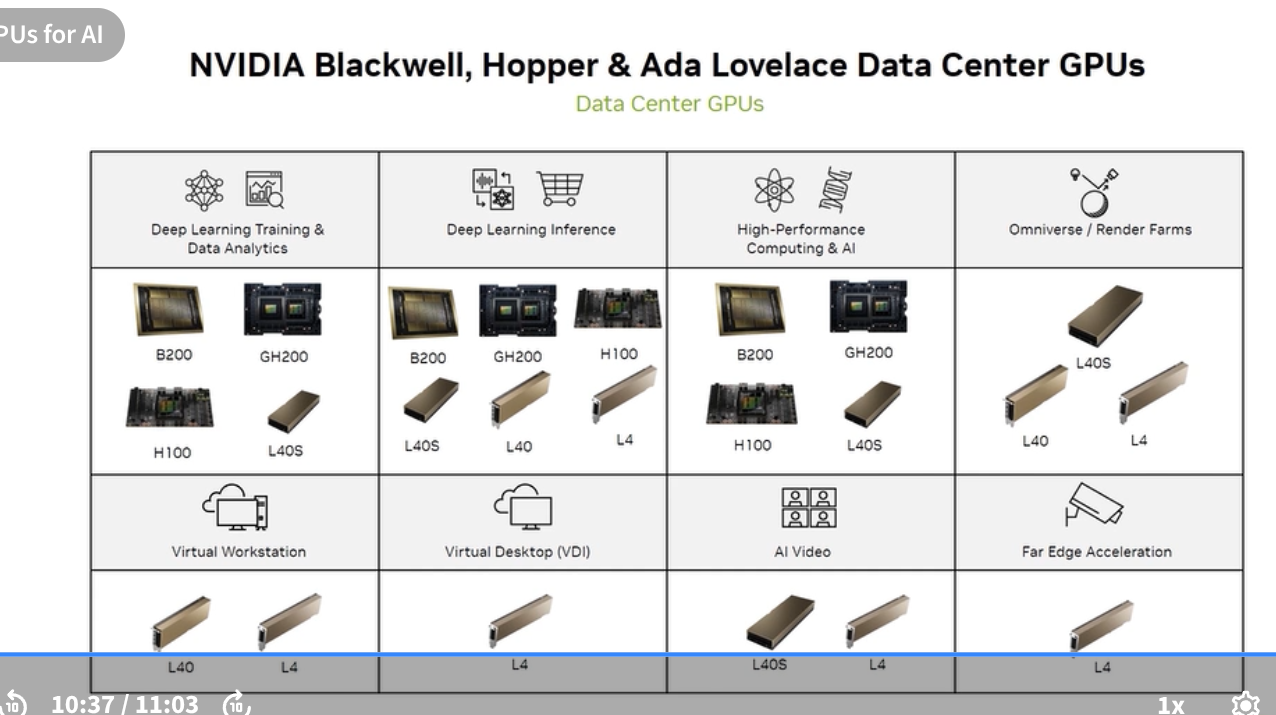
NVIDIA’s official workload-to-GPU mapping:
| Workload | Recommended GPUs | Why |
|---|---|---|
| Deep Learning Training & Data Analytics | B200, GH200, H100, L40S | Highest FLOPS + HBM bandwidth for gradient compute |
| Deep Learning Inference | B200, GH200, H100, L40S, L40, L4 | Wide range; choose by model size and latency req |
| HPC & Scientific Computing & AI | B200, GH200, H100, L40S | FP64 compute (H100), large memory capacity |
| Omniverse / Render Farms | L40S | RT Cores + GPU rendering; no need for HBM |
| Virtual Workstation | L40 | Professional graphics + AI |
| Virtual Desktop (VDI) | L4 | Power-efficient; vGPU support; 72W TDP |
| AI Video | L40S, L4 | Hardware video encode/decode engines |
| Far Edge Acceleration | L4 | Low power; fits in standard PCIe slots |
Hardware dimensions that determine GPU selection
1. GPU Memory (VRAM)
The model must fit in GPU memory — if it doesn’t, either use model parallelism across multiple GPUs or use a GPU with more memory.
| GPU | Memory | Type |
|---|---|---|
| H100 SXM5 | 80 GB | HBM3 |
| H200 SXM5 | 141 GB | HBM3e |
| B200 SXM | 192 GB | HBM3e |
| L40S | 48 GB | GDDR6 |
| L4 | 24 GB | GDDR6 |
Rule of thumb for LLM inference: A 70B parameter model in FP16 requires ~140 GB GPU memory (2 bytes × 70B). Needs 2× H100 SXM (80GB each) or 1× B200 (192GB).
2. Memory Bandwidth
Critical for inference (memory-bound at small batch sizes) and training (loading weights/activations between compute steps).
| GPU | Memory Bandwidth |
|---|---|
| H100 SXM5 | 3.35 TB/s |
| H200 SXM5 | 4.8 TB/s |
| B200 | ~8 TB/s |
| L40S | 864 GB/s |
3. Compute FLOPS (Tensor Core throughput)
Critical for large-batch training. More FLOPS = more samples processed per second.
| GPU | Peak (BF16 Tensor Core) |
|---|---|
| A100 80GB | 312 TFLOPS |
| H100 SXM5 | 989 TFLOPS |
| B200 | ~2,250 TFLOPS |
4. Interconnect (for multi-GPU)
When the model or data doesn’t fit on one GPU, GPUs must communicate. Bandwidth here is often the bottleneck.
- NVLink (within node): 900 GB/s (NVLink 4, Hopper) → 1.8 TB/s (NVLink 5, Blackwell)
- NVSwitch (within system): enables all-to-all NVLink across 8 GPUs in DGX
- InfiniBand (across nodes): 200/400/800 Gbps per link; required for multi-node training
5. Form factor
- SXM: High-performance slot; liquid-cooled; used in DGX systems; highest power envelope (700W–1000W per GPU)
- PCIe: Standard server card; air or liquid cooled; lower max TDP; broader server compatibility
- OAM (OCP Accelerator Module): Used in custom hyperscaler platforms
Sizing example: LLM pre-training cluster
Suppose you’re pre-training a 70B parameter LLM with Hopper H100s:
| Requirement | Detail |
|---|---|
| Model memory per GPU | 70B × 2 bytes (BF16) = 140 GB → minimum 2× H100 80GB for weights alone |
| Optimizer states | ~4× model memory in mixed precision → total ~560 GB |
| Training cluster | 8-GPU DGX H100 node minimum; typically 64–512 nodes |
| Network | NDR InfiniBand 400Gbps per link between nodes |
| Storage | High-throughput parallel FS (WEKA/Lustre) feeding training data |
Self-check questions
- Which GPU is recommended for Virtual Desktop Infrastructure (VDI)?
- A 141 GB model in FP16 must fit on a single GPU for inference. Which GPU can hold it?
- Why is memory bandwidth more important than FLOPS for inference at low batch sizes?
- What is the difference between SXM and PCIe form factors?
- Which two interconnects are required for large-scale multi-node LLM training?
Answers
1. NVIDIA L4 — 24 GB GDDR6, 72W TDP, vGPU support, optimized for VDI workloads.2. H200 SXM5 (141 GB HBM3e) — exactly fits the model.
3. At low batch sizes, the GPU spends most time loading model weights from memory (memory-bound). FLOPS only become the bottleneck at large batch sizes where compute is actually sustained. For LLM token generation (batch=1), bandwidth directly limits tokens/second.
4. SXM is a high-bandwidth slot used in DGX systems, supports the highest TDP (700–1000W) and full NVLink bandwidth. PCIe uses standard server slots, lower max TDP, compatible with any server — more flexible but lower peak performance.
5. NVLink/NVSwitch (within each node for all-to-all GPU communication) and InfiniBand (between nodes for gradient all-reduce across the cluster).